Datenbanken sind überall um uns herum - von Spotify bis...
Einführung in Datenbanken: Grundlagen und SQL-Übungen
dmstjf@dms_tjf



1 / 10
1
of 10
Grundlagen von Datenbanken
Stell dir vor, du müsstest alle Kontakte deiner Freunde in einem riesigen Stapel Zettel verwalten - chaotisch, oder? Datenbanken lösen genau dieses Problem, indem sie Informationen in einer festen Struktur speichern.
Eine Datenbank (DB) ist einfach die Sammlung aller Daten, die du verwalten willst. Das Datenbankmanagementsystem (DBMS) ist die Software, die diese Daten organisiert - wie ein super intelligenter Bibliothekar. Zusammen bilden sie das Datenbanksystem (DBS).
Relationale Datenbanken funktionieren wie Excel-Tabellen auf Steroiden. Jede Tabelle hat einen eindeutigen Namen, Spalten (Attribute) mit festgelegten Datentypen und beliebig viele Zeilen (Datensätze). Wichtig: Jeder Wert muss atomar sein - also keine Listen in einer Zelle!
Merkhilfe: DB = Daten, DBMS = Software, DBS = beide zusammen
2
of 10
Vorteile und Struktur von Datenbanksystemen
Im Gegensatz zu Excel können echte Datenbanksysteme mehrere Benutzer gleichzeitig arbeiten lassen - ohne nervigen Schreibschutz. Perfekt für Teams oder große Anwendungen wie das Bahnsystem, wo Fahrplanauskunft, Infotafeln und Schaffner-Apps alle auf dieselben Daten zugreifen.
Datenbanksysteme arbeiten in drei Ebenen: Die externe Ebene zeigt dir nur das, was du brauchst (wie verschiedene Apps). Die konzeptionelle Ebene organisiert alles unabhängig von den Programmen. Die physische Ebene kümmert sich um Speicherung und Performance.
Primärschlüssel sind wie Personalausweise für deine Datensätze - sie machen jeden eindeutig identifizierbar. Fremdschlüssel verbinden Tabellen miteinander, indem sie auf Primärschlüssel anderer Tabellen verweisen.
Praxistipp: Schema-Notation hilft dir, Tabellenstrukturen schnell zu verstehen: Tabelle(Primärschlüssel, Fremdschlüssel↑, weitere Attribute)
3
of 10
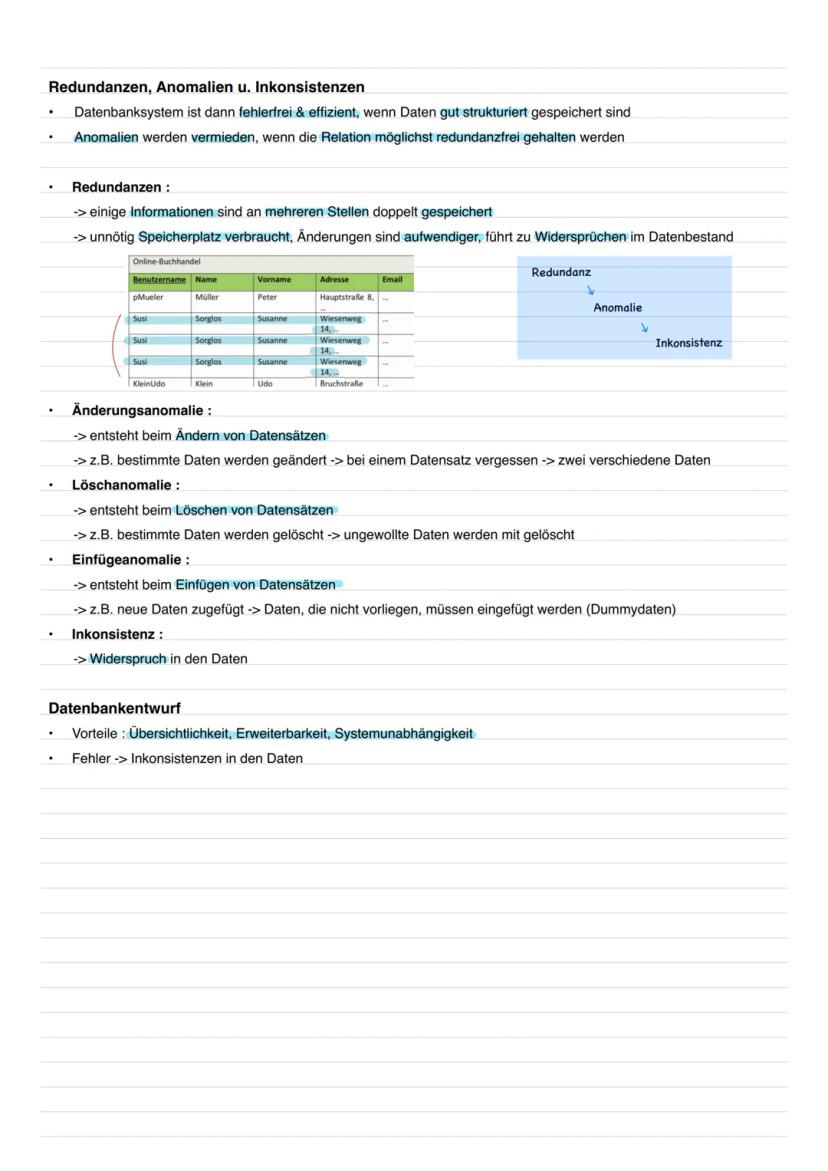
Probleme schlecht strukturierter Datenbanken
Wenn deine Datenbank schlecht geplant ist, wird sie zum Alptraum. Redundanzen entstehen, wenn dieselben Informationen mehrfach gespeichert werden - das verschwendet Speicher und führt zu Chaos.
Änderungsanomalien treten auf, wenn du Daten aktualisieren willst, aber einen Datensatz übersiehst. Plötzlich hat dieselbe Person zwei verschiedene Adressen! Löschanomalien sind noch fieser: Du löschst einen Kunden und verlierst dabei ungewollt wichtige Produktdaten.
Einfügeanomalien zwingen dich, Dummydaten einzugeben, nur weil die Tabellenstruktur es verlangt. All diese Probleme führen zu Inkonsistenzen - Widersprüchen in deinen Daten.
Faustregel: Eine gut strukturierte Datenbank vermeidet Redundanzen und macht Änderungen einfach und sicher.
4
of 10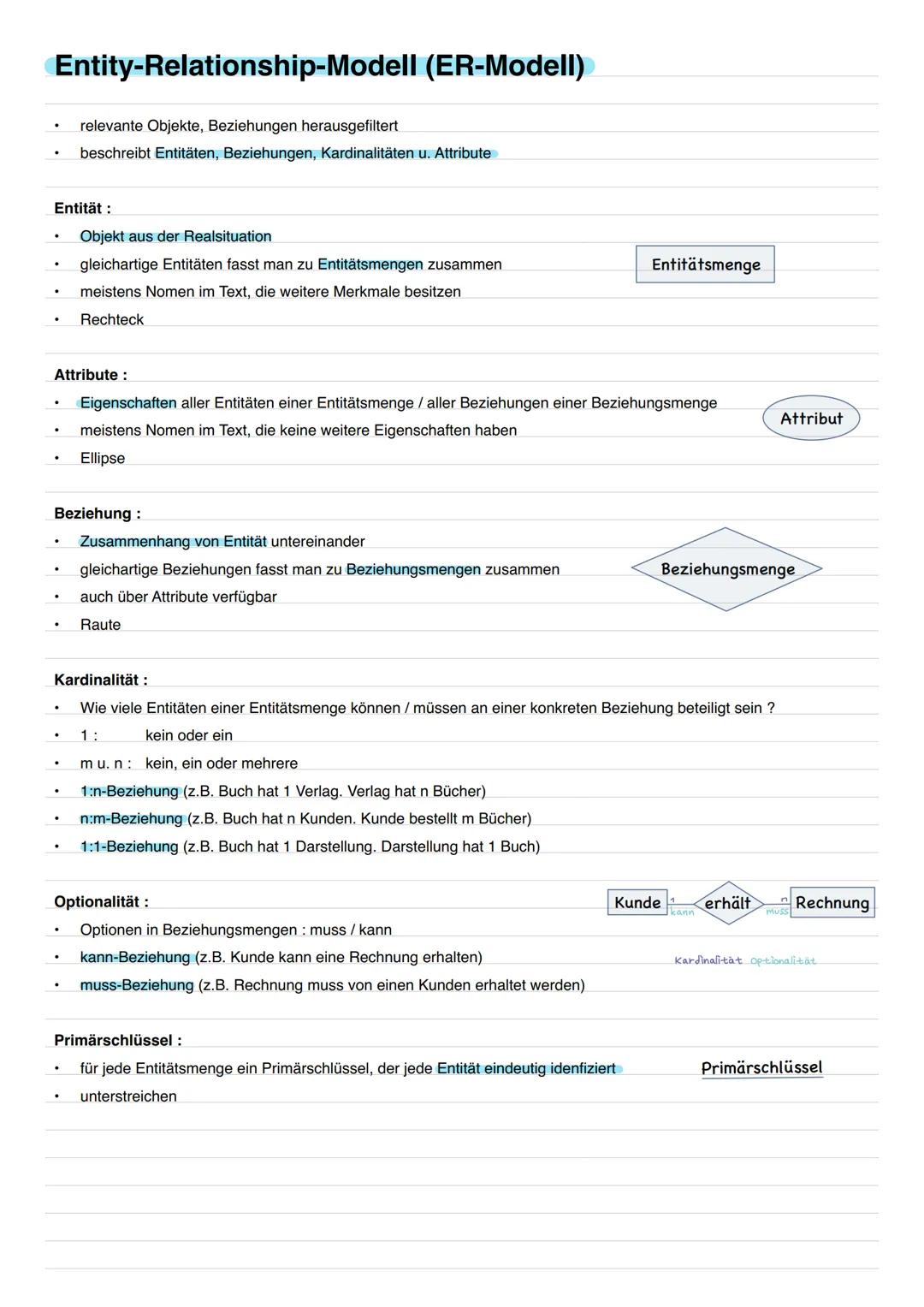
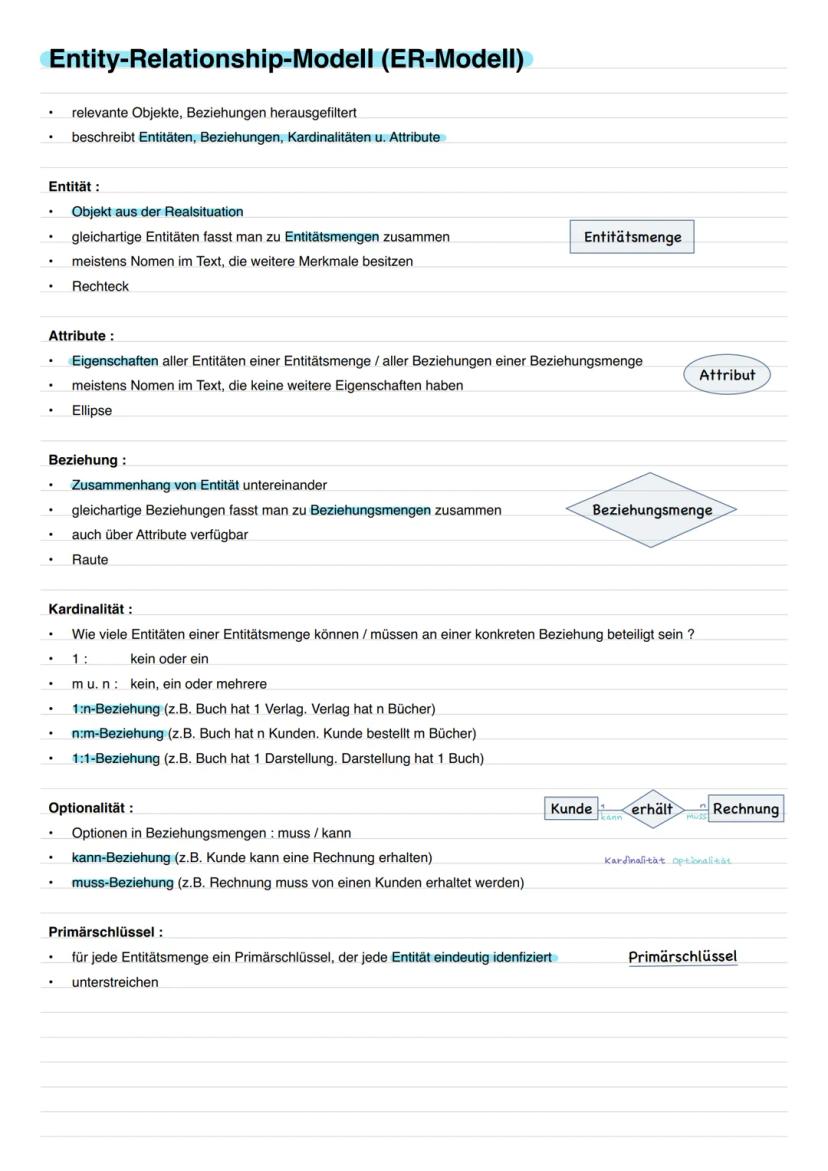
Entity-Relationship-Modell (ER-Modell)
Das ER-Modell ist wie ein Bauplan für deine Datenbank. Du identifizierst Entitäten (Objekte aus der Realität wie "Kunde" oder "Buch"), Attribute (Eigenschaften wie Name oder Preis) und Beziehungen (Zusammenhänge zwischen Entitäten).
Kardinalitäten beschreiben, wie viele Objekte miteinander verbunden sein können. Eine 1:n-Beziehung bedeutet: Ein Verlag hat viele Bücher, aber jedes Buch hat nur einen Verlag. Bei n:m-Beziehungen kann ein Kunde mehrere Bücher bestellen und ein Buch von mehreren Kunden bestellt werden.
Optionalität zeigt, ob eine Beziehung zwingend ist: Ein Kunde kann eine Rechnung erhalten (optional), aber eine Rechnung muss von einem Kunden stammen (Pflicht). Primärschlüssel werden im ER-Diagramm unterstrichen dargestellt.
Zeichentrick: Rechteck = Entität, Ellipse = Attribut, Raute = Beziehung - so einfach ist die ER-Notation!
5
of 10
Vom ER-Modell zur relationalen Datenbank
Jetzt wird's praktisch! Entitätstypen werden zu eigenständigen Tabellen, wobei der Primärschlüssel unterstrichen am Anfang steht. Die Attribute werden zu Spalten deiner Tabelle.
Beziehungen behandelst du je nach Typ unterschiedlich: m:n-Beziehungen bekommen eine eigene Tabelle. 1:n-Beziehungen ohne eigene Attribute löst du über Fremdschlüssel - der Primärschlüssel der "1"-Seite wandert als Fremdschlüssel zur "n"-Seite.
1:1-Beziehungen hängen von der Optionalität ab: Bei "kann-muss"-Beziehungen kommt der Primärschlüssel der "kann"-Seite als Fremdschlüssel zur "muss"-Seite. Die Farbcodierung hilft: Grün = eine Relation, Rot = zwei Relationen, Blau = drei Relationen.
Praxistipp: Lerne die Farbcodierung der Optimierungstabelle - sie spart dir viel Zeit bei der Umsetzung!
6
of 10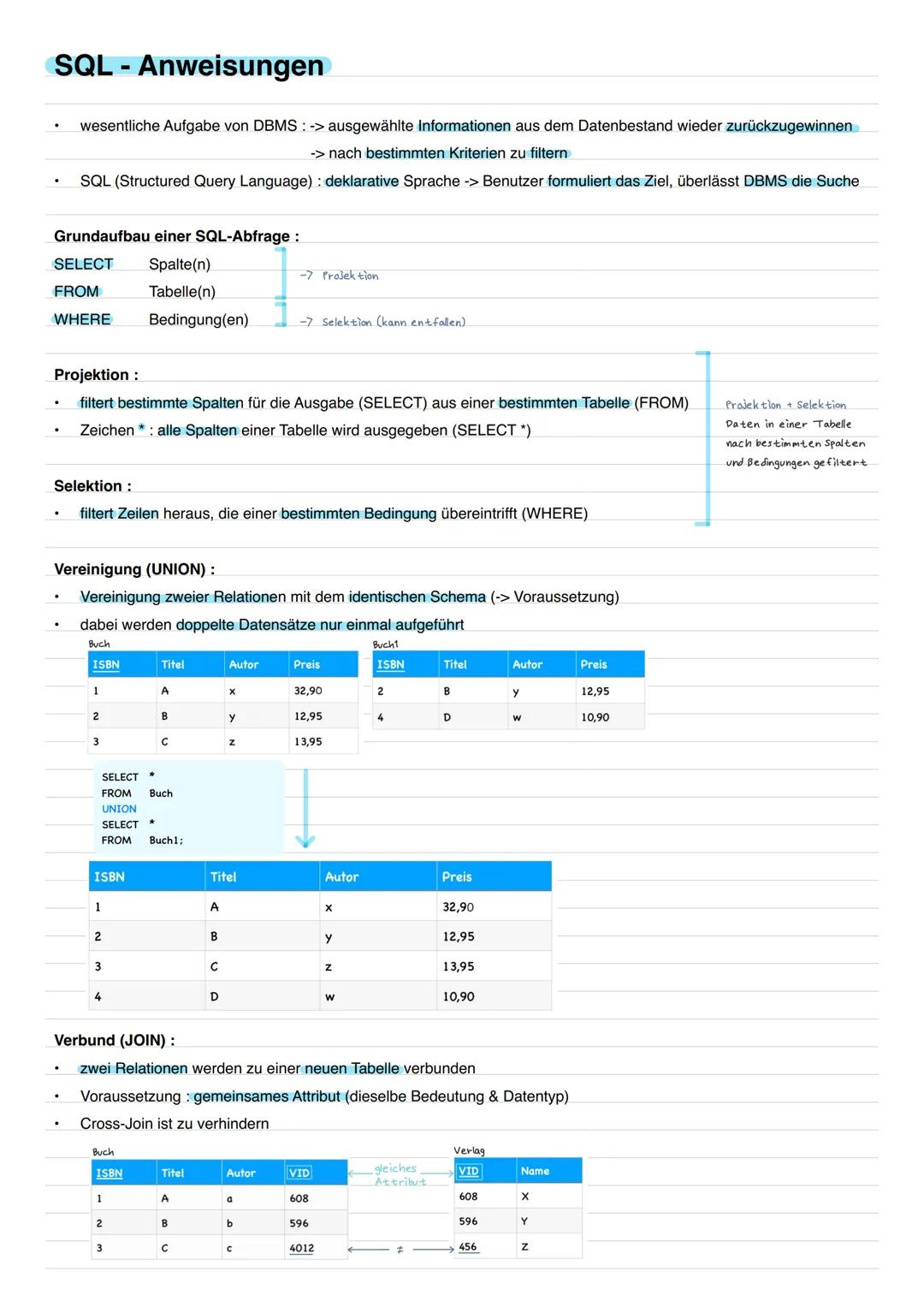
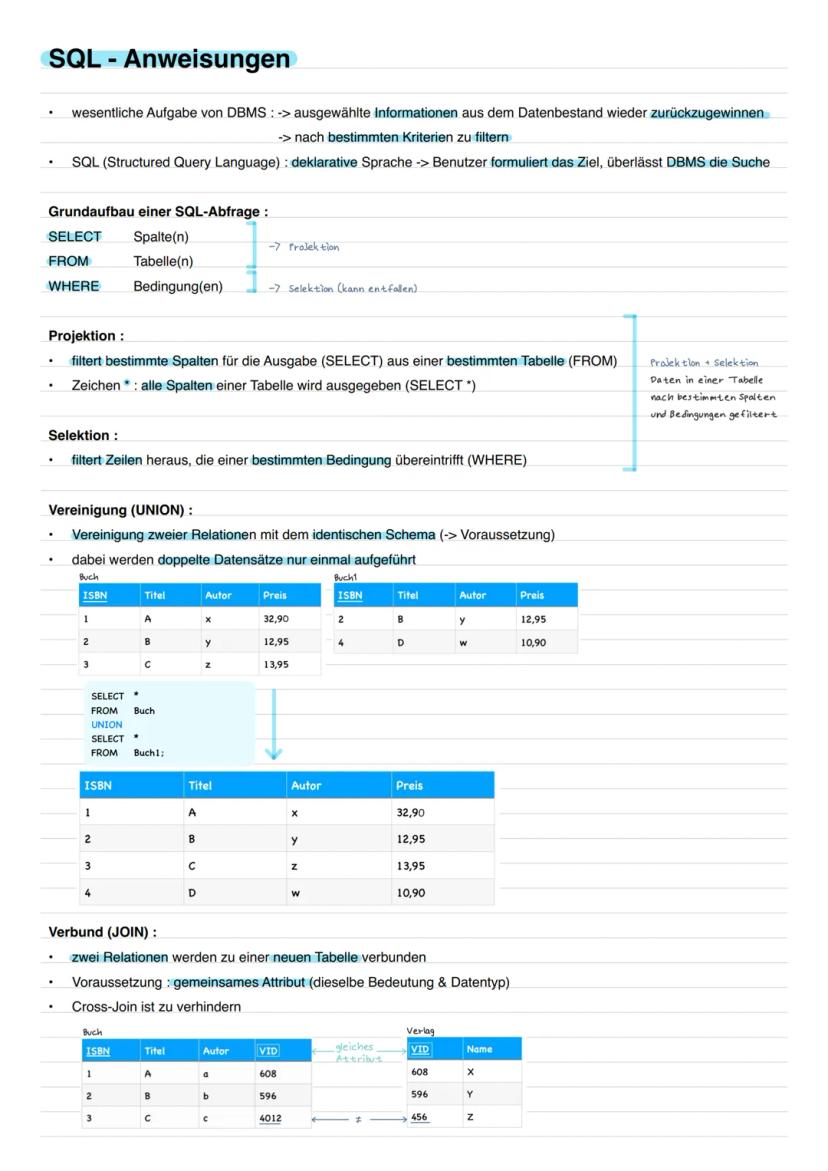
SQL-Grundlagen: Daten abfragen
SQL (Structured Query Language) ist deine Sprache, um mit der Datenbank zu sprechen. Der Grundaufbau ist simpel: SELECT (welche Spalten?), FROM (aus welcher Tabelle?), WHERE (unter welchen Bedingungen?).
Projektion filtert bestimmte Spalten heraus (SELECT Spalte FROM Tabelle). Mit dem Stern (SELECT *) holst du alle Spalten. Selektion filtert Zeilen nach Bedingungen (WHERE Bedingung).
UNION vereinigt zwei Tabellen mit identischem Schema - doppelte Einträge werden automatisch entfernt. JOIN verbindet zwei Tabellen über gemeinsame Attribute. Wichtig: Vermeide Cross-Joins, die jede Zeile der ersten mit jeder der zweiten Tabelle kombinieren!
Merksatz: SELECT = Spalten wählen, WHERE = Zeilen filtern, FROM = Tabelle angeben
7
of 10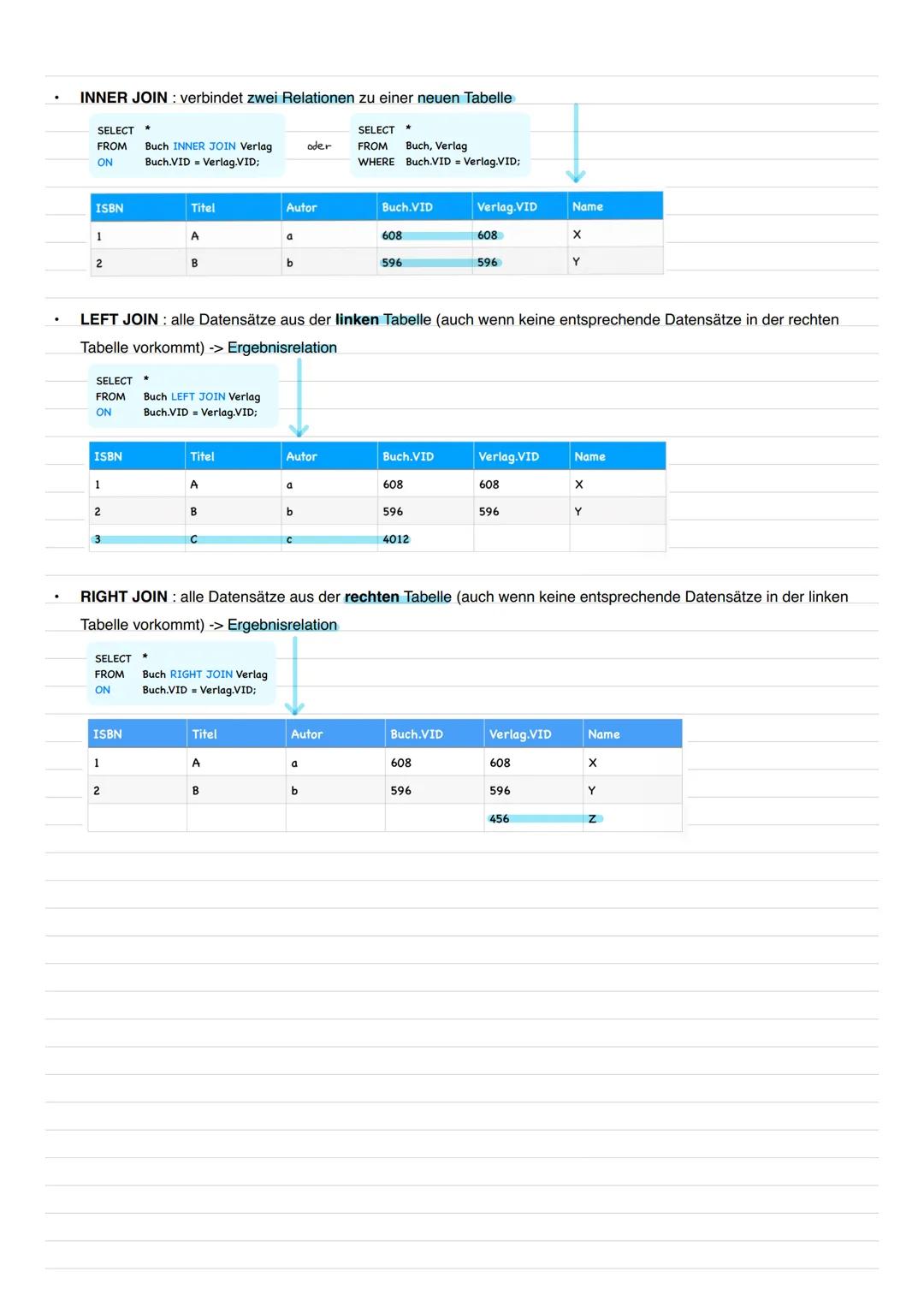
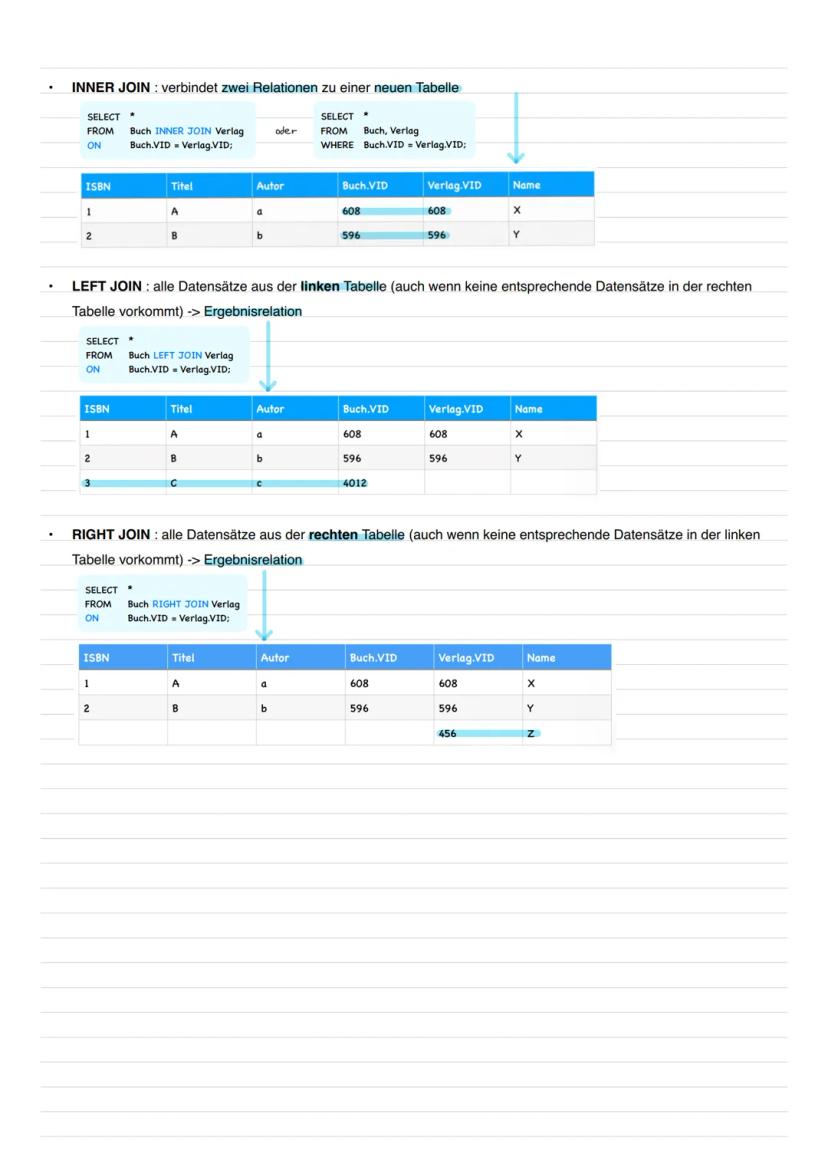
JOIN-Varianten in SQL
INNER JOIN verbindet nur Datensätze, die in beiden Tabellen Entsprechungen haben. Das ist der Standard-Join für die meisten Abfragen. Die Syntax: FROM Tabelle1 INNER JOIN Tabelle2 ON Bedingung.
LEFT JOIN behält alle Datensätze der linken Tabelle, auch wenn keine Entsprechung in der rechten existiert. Fehlende Werte werden als NULL dargestellt. RIGHT JOIN macht das Gegenteil - alle Datensätze der rechten Tabelle bleiben erhalten.
Die Wahl des richtigen Joins hängt davon ab, welche Daten du behalten willst. INNER JOIN für exakte Übereinstimmungen, LEFT/RIGHT JOIN wenn du auch "unvollständige" Datensätze brauchst.
Eselsbrücke: LEFT JOIN = linke Tabelle vollständig, RIGHT JOIN = rechte Tabelle vollständig, INNER JOIN = nur Übereinstimmungen
8
of 10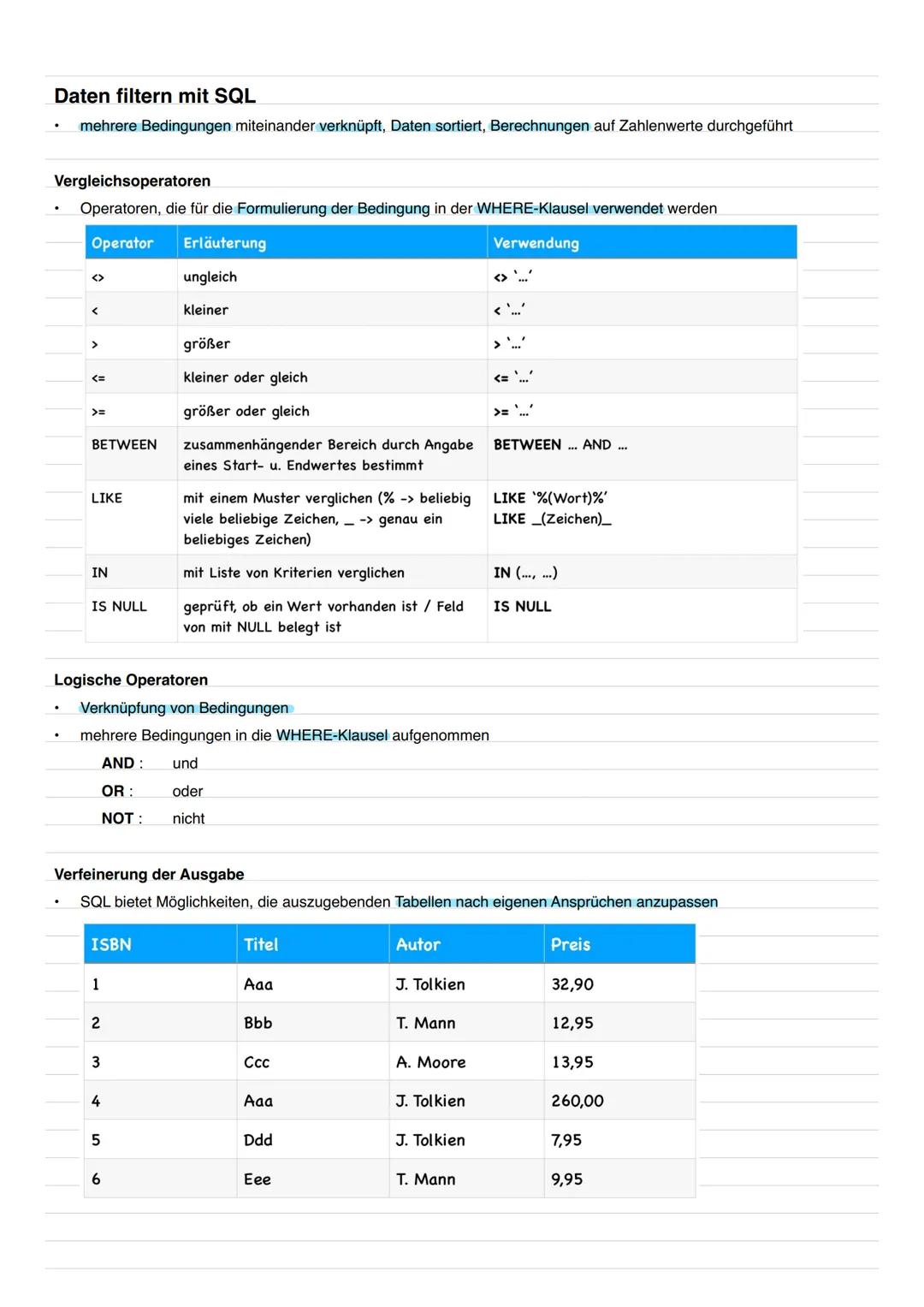
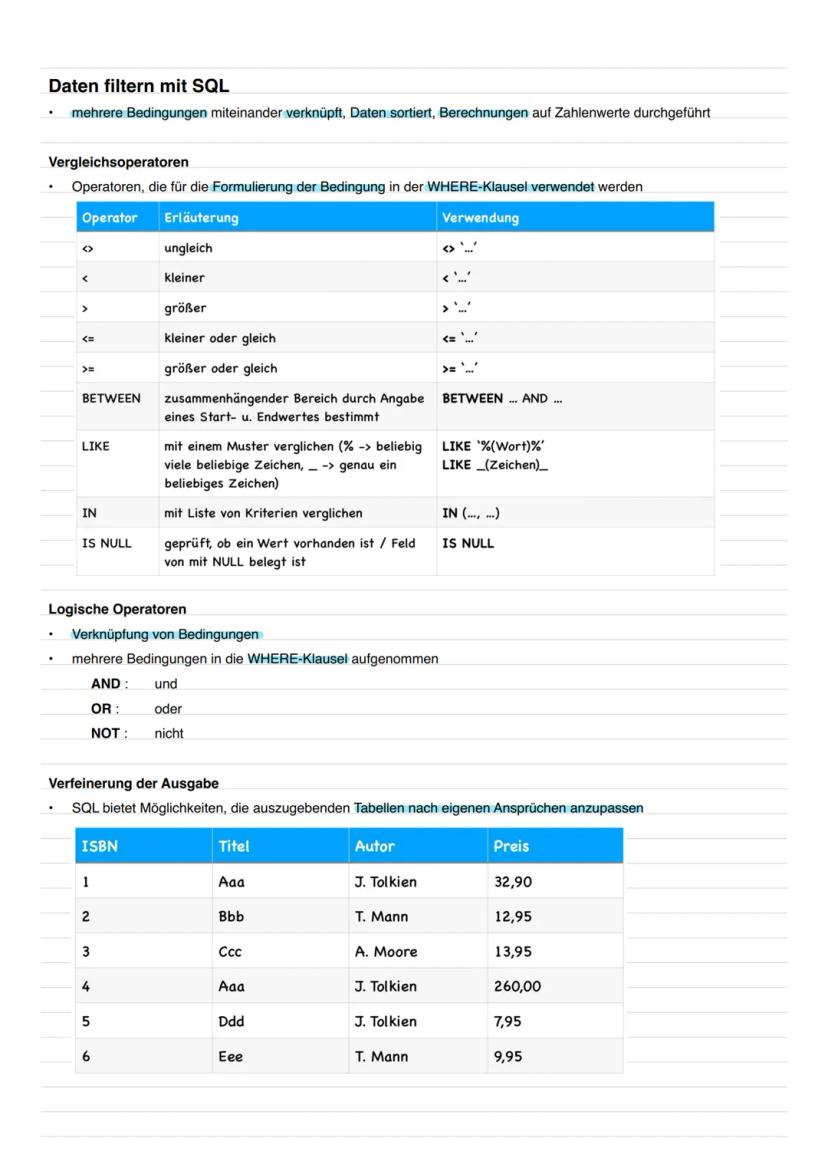
Daten filtern und vergleichen
Vergleichsoperatoren machen deine WHERE-Klauseln mächtig. Neben den üblichen (<, >, =) gibt es praktische Helfer: BETWEEN für Bereiche, LIKE mit Wildcards (% für beliebig viele, _ für genau ein Zeichen) und IN für Listen.
Logische Operatoren (AND, OR, NOT) verknüpfen mehrere Bedingungen. IS NULL prüft auf leere Felder - wichtig, da NULL-Werte sich anders verhalten als normale Werte.
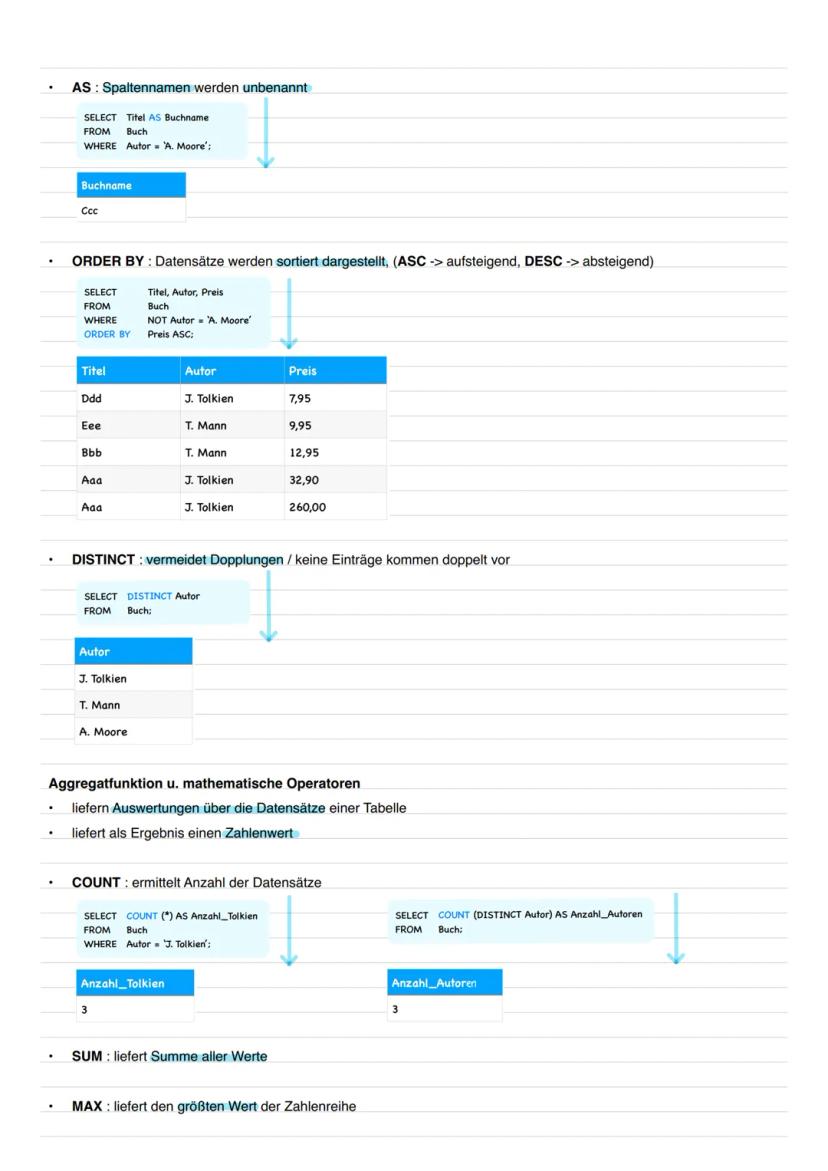
Die Verfeinerung der Ausgabe macht deine Ergebnisse professioneller: AS benennt Spalten um, ORDER BY sortiert (standardmäßig aufsteigend), DISTINCT entfernt Duplikate.
Tipp für die Praxis: LIKE-Wildcards sind super für Suchfunktionen -
LIKE '%Mueller%'findet "Mueller", "Müller" und "von Mueller"
9
of 10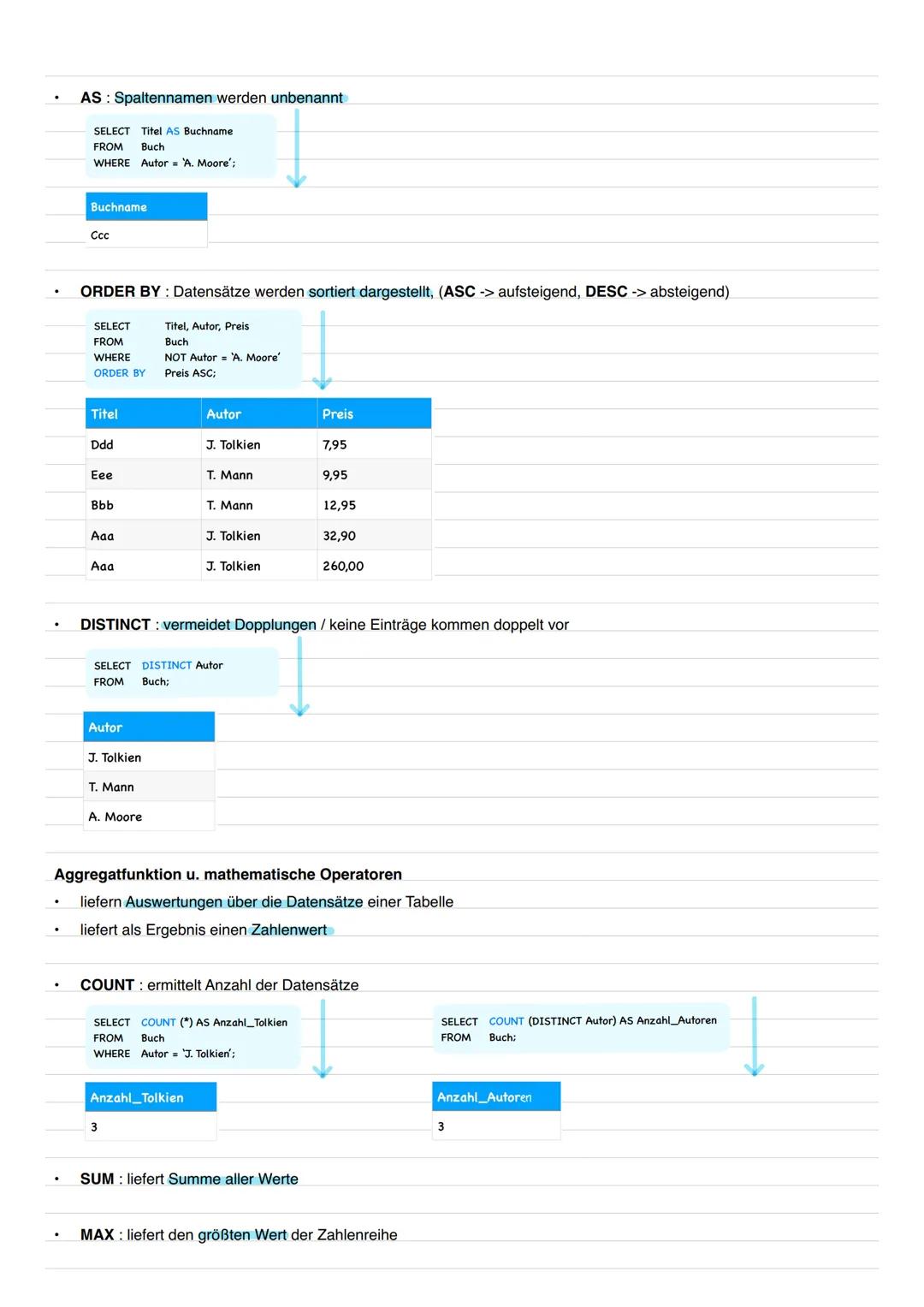
Aggregatfunktionen und Berechnungen
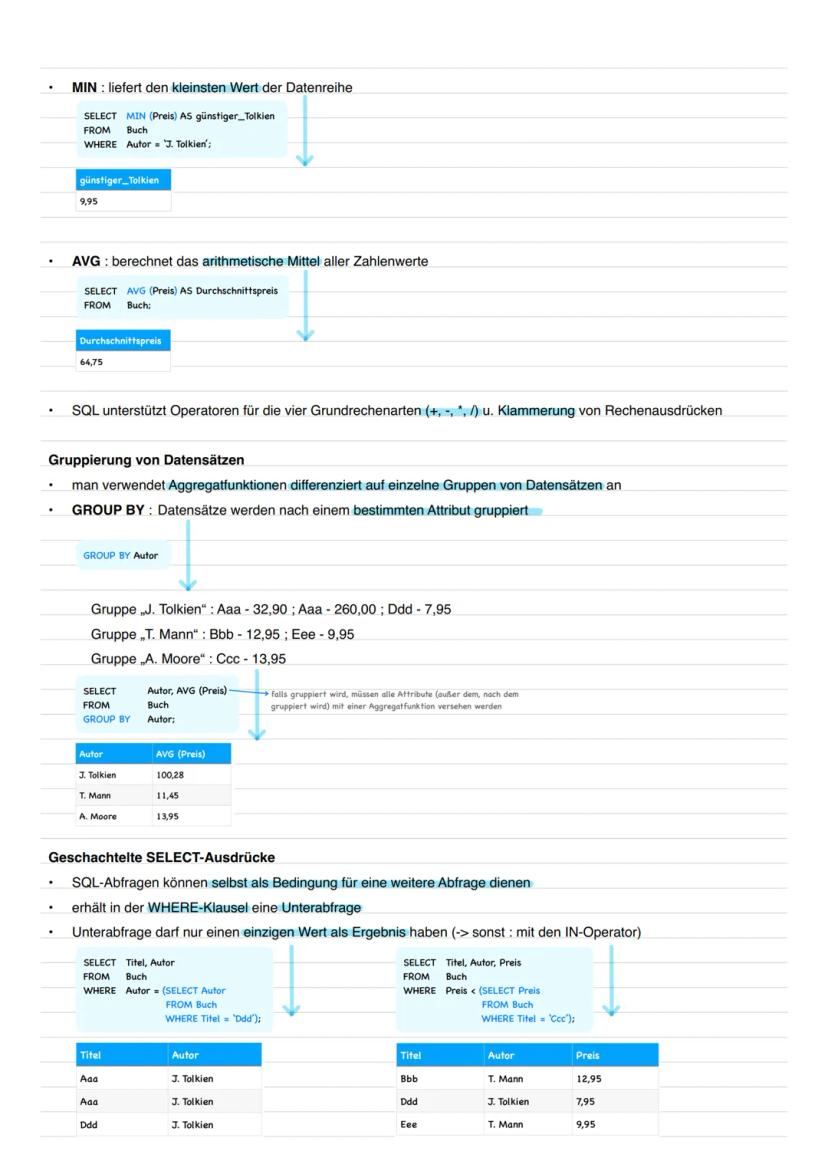
Aggregatfunktionen fassen Daten zusammen und liefern einzelne Zahlenwerte. COUNT(*) zählt alle Datensätze, COUNT(DISTINCT Spalte) nur die verschiedenen Werte. SUM, MAX, MIN und AVG arbeiten mit Zahlenwerten.
Mathematische Operatoren (+, -, *, /) funktionieren auch in SQL. Du kannst direkt in der SELECT-Klausel rechnen oder Spalten miteinander verknüpfen.
Die Gruppierung mit GROUP BY teilt deine Daten in Gruppen auf und wendet Aggregatfunktionen auf jede Gruppe einzeln an. Wichtig: Alle Spalten im SELECT müssen entweder in GROUP BY stehen oder eine Aggregatfunktion haben.
Häufiger Fehler: Wenn du GROUP BY verwendest, müssen alle nicht-gruppierten Spalten eine Aggregatfunktion haben!
10
of 10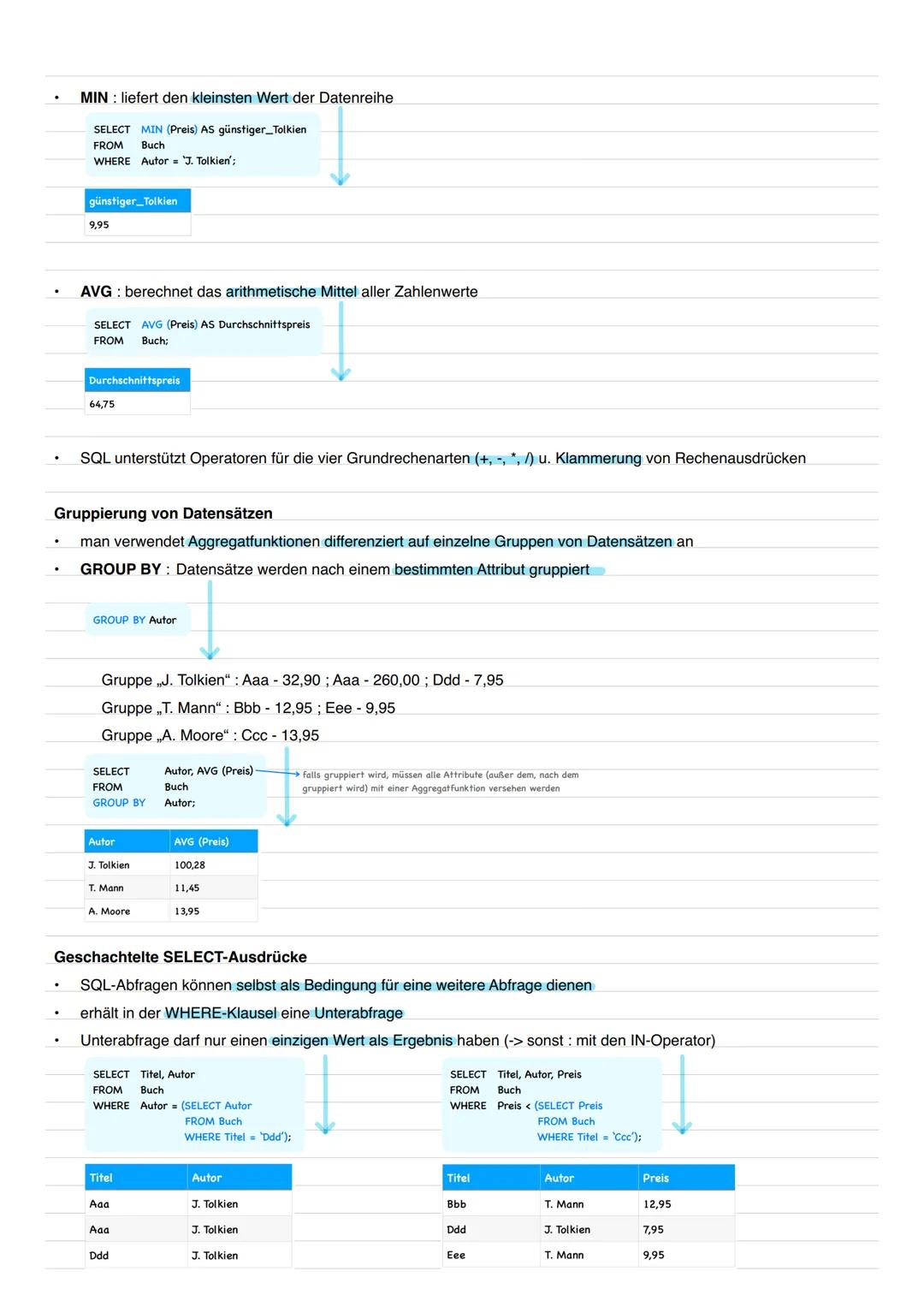
Erweiterte SQL-Techniken
Geschachtelte SELECT-Ausdrücke (Unterabfragen) machen komplexe Abfragen möglich. Die innere Abfrage läuft zuerst und ihr Ergebnis wird als Bedingung für die äußere verwendet. Bei mehreren Ergebniswerten nutzt du den IN-Operator.
Aggregatfunktionen wie MIN und AVG helfen bei statistischen Auswertungen. Du kannst sie mit WHERE-Bedingungen kombinieren, um nur bestimmte Datensätze zu berücksichtigen.
Komplexere Abfragen entstehen durch Kombination verschiedener Techniken: JOINs mit Aggregatfunktionen, Unterabfragen mit Gruppierungen oder mehrere WHERE-Bedingungen mit logischen Operatoren.
Profi-Tipp: Teste komplexe Abfragen schrittweise - baue sie von innen nach außen oder von einfach zu komplex auf
Wir dachten schon, du fragst nie...
Unser KI-Begleiter ist ein speziell für Schüler entwickeltes KI-Tool, das mehr als nur Antworten bietet. Basierend auf Millionen von Knowunity-Inhalten liefert er relevante Informationen, personalisierte Lernpläne, Quizze und Inhalte direkt im Chat und passt sich deinem individuellen Lernweg an.
Du kannst die App im Google Play Store und im Apple App Store herunterladen.
Genau! Genieße kostenlosen Zugang zu Lerninhalten, vernetze dich mit anderen Schülern und hol dir sofortige Hilfe – alles direkt auf deinem Handy.
Ähnlicher Inhalt
Beliebtester Inhalt: SQL
2SQL-Befehle und Datenbankmodellierung
Erfahren Sie alles über grundlegende SQL-Befehle wie INSERT, SELECT, UPDATE und DELETE sowie die Modellierung relationaler Datenbanken. Diese Zusammenfassung behandelt auch das Entity-Relationship-Modell, Datenbanknormalisierung und wichtige SQL-Klauseln wie WHERE, GROUP BY und HAVING. Ideal für Studierende der Informatik, die ihre Kenntnisse in relationalen Datenbanken vertiefen möchten.
1210,634323
Webentwicklung Grundlagen
Erfahren Sie die Grundlagen der Webentwicklung mit HTML, CSS und PHP. Dieser umfassende Leitfaden behandelt die Erstellung von Webseiten, Datenbankanlegung mit SQL, Datenbanknormalisierung und die Verwendung von JOIN-Abfragen. Ideal für Abiturienten, die sich auf das Fach Informationsverarbeitung vorbereiten.
131,39638
Beliebtester Inhalt in Informatik
9Q
Quiz für die Komponenten des Pc's💻
💻Hier lernst ind testest du dein wissen über die Pc Komponenten⌨️
65974
C
Computer
Lerne alles über Computer und ihre Funktionsweise mit diesen fesselnden Flashcards. Perfekt für Schüler der 5. Klasse, die Computer Science entdecken möchten.
55440
Informatik Abitur 2025 NRW
Informatik Übersicht zu den Themen die im mündlichen Abitur drankommen. Ist also vielleicht nicht zu 100% vollständig.
124679
Informatik GK Lernzettel Abitur 2025
- selbstständig erstellter Lernzettel
1279118
WENN und SVERWEIS
Erklärung sverweis und wenn Funktion bei exel
116263
Python Lernzettel Informatik
Python Lernzettel (mathematische Operatoren, Variablen, Datentypen, Skripte, Boolesche Operatoren)
118899
Informatik Abitur 2024: Themenübersicht
Umfassende Themenübersicht für das Abitur 2024 im Fach Informatik. Dieser Lernzettel deckt wichtige Konzepte wie Programmierung in Java, Algorithmen, Datenstrukturen, Datenbanken, Cybersecurity und Verschlüsselungsmethoden ab. Ideal für Schüler, die sich auf das erhöhte Anforderungsniveau vorbereiten. Enthält auch Informationen zu relationalen Datenbanken, SQL-Abfragen und kryptologischen Verfahren.
132,86659
Relationale Datenbanken und SQL
Diese Zusammenfassung bietet einen umfassenden Überblick über relationale Datenbanken, einschließlich der Definition von Datensätzen, Attributen, Primär- und Fremdschlüsseln. Erfahren Sie mehr über Anomalien, ER-Diagramme und die Formulierung von SQL-Abfragen, um Daten effizient zu verwalten und zu analysieren. Ideal für Informatik-Abiturienten.
132,61765
Excel: Tabellen & Funktionen
Entdecken Sie die Grundlagen der Tabellenformatierung, wichtige Excel-Funktionen wie SUMME, MAX und WENN sowie die Erstellung von Diagrammen. Diese Zusammenfassung bietet klare Beispiele und Anleitungen für effektives Arbeiten mit Excel. Ideal für Studierende, die ihre Excel-Kenntnisse vertiefen möchten.
4,188139
Beliebtester Inhalt
9Der zerbrochene Krug
Szenenzusammenfassunfen, Figurenkonstellationen, Aufbau des Stücks, Sprache und Stilbesonderheiten, Aussageabsicht, Thematik, Interpretation
1148,107729
Heimsuchung_JennyErpenbeck_Abitur
Zusammenfassungen für jedes Kapitel, Analysen und Zitate
1314,164277
Lernzettel ZP 10 Mathe
Lernzettel von der ZP 10
105,350116
Schreibkompetenzen Deutsch LK
Diese umfassende Zusammenstellung bereitet auf das Abitur 2024 vor und deckt alle relevanten Schreibkompetenzen ab: von der Analyse pragmatischer Texte über die Erörterung literarischer Werke bis hin zur Interpretation von Epik, Lyrik und Dramatik. Zudem werden Techniken des materialgestützten Schreibens, der Redeanalyse sowie journalistische Textsorten und rhetorische Mittel behandelt. Ideal für eine gezielte und effektive Prüfungsvorbereitung.
138,223165
Mathe ZP10 Zusammenfassung NRW
Zusammenfassung der Mathethemwn für die ZP10 NRW + Formelsammlung
1010,195518
Der zerbrochene Krug Lernzettel & Zusammenfassung
Der zerbrochene Krug, Die wichtigsten Informationen zusammengefasst, Lernzettel
1323,506356
1
10 unregelmäßige Verben im past participle
unregelmäßige Verben aus Englisch - past participle
64,2783
Heimsuchung - Jenny Erpenbeck
Inhalt, Entstehung und Quellen, Figuren, Geschichtliche Hintergründe, Motive, Erzählstruktur/- stil
1134,810655
Führerschein Theorie Wiederholung/Notizen
Schilder, Zeichen, Zahlen, Vorfahrt und mehr - alles für die theoretische Führerscheinprüfung :)
119,082149
Schüler lieben uns — und du auch.
4.6/5App Store
4.7/5Google Play
Die App ist sehr einfach zu bedienen und gut gestaltet. Ich habe bisher alles gefunden, wonach ich gesucht habe, und konnte viel aus den Präsentationen lernen! Ich werde die App definitiv für ein Schulprojekt nutzen! Und natürlich hilft sie auch sehr als Inspiration.
Stefan SiOS-Nutzer
Diese App ist wirklich super. Es gibt so viele Lernzettel und Hilfen [...]. Mein Problemfach ist zum Beispiel Französisch und die App hat so viele Möglichkeiten zur Hilfe. Dank dieser App habe ich mich in Französisch verbessert. Ich würde sie jedem empfehlen.
Samantha KlichAndroid-Nutzerin
Wow, ich bin wirklich begeistert. Ich habe die App einfach mal ausprobiert, weil ich sie schon oft beworben gesehen habe und war absolut beeindruckt. Diese App ist DIE HILFE, die man für die Schule braucht und vor allem bietet sie so viele Dinge wie Übungen und Lernzettel, die mir persönlich SEHR geholfen haben.
AnnaiOS-Nutzerin
Einführung in Datenbanken: Grundlagen und SQL-Übungen
dmstjf@dms_tjf
Datenbanken sind überall um uns herum - von Spotify bis zur Bahn-App. Du lernst hier, wie Informationen strukturiert gespeichert und clever abgerufen werden können.
1
of 10
Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
Grundlagen von Datenbanken
Stell dir vor, du müsstest alle Kontakte deiner Freunde in einem riesigen Stapel Zettel verwalten - chaotisch, oder? Datenbanken lösen genau dieses Problem, indem sie Informationen in einer festen Struktur speichern.
Eine Datenbank (DB) ist einfach die Sammlung aller Daten, die du verwalten willst. Das Datenbankmanagementsystem (DBMS) ist die Software, die diese Daten organisiert - wie ein super intelligenter Bibliothekar. Zusammen bilden sie das Datenbanksystem (DBS).
Relationale Datenbanken funktionieren wie Excel-Tabellen auf Steroiden. Jede Tabelle hat einen eindeutigen Namen, Spalten (Attribute) mit festgelegten Datentypen und beliebig viele Zeilen (Datensätze). Wichtig: Jeder Wert muss atomar sein - also keine Listen in einer Zelle!
Merkhilfe: DB = Daten, DBMS = Software, DBS = beide zusammen
2
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
Vorteile und Struktur von Datenbanksystemen
Im Gegensatz zu Excel können echte Datenbanksysteme mehrere Benutzer gleichzeitig arbeiten lassen - ohne nervigen Schreibschutz. Perfekt für Teams oder große Anwendungen wie das Bahnsystem, wo Fahrplanauskunft, Infotafeln und Schaffner-Apps alle auf dieselben Daten zugreifen.
Datenbanksysteme arbeiten in drei Ebenen: Die externe Ebene zeigt dir nur das, was du brauchst (wie verschiedene Apps). Die konzeptionelle Ebene organisiert alles unabhängig von den Programmen. Die physische Ebene kümmert sich um Speicherung und Performance.
Primärschlüssel sind wie Personalausweise für deine Datensätze - sie machen jeden eindeutig identifizierbar. Fremdschlüssel verbinden Tabellen miteinander, indem sie auf Primärschlüssel anderer Tabellen verweisen.
Praxistipp: Schema-Notation hilft dir, Tabellenstrukturen schnell zu verstehen: Tabelle(Primärschlüssel, Fremdschlüssel↑, weitere Attribute)
3
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
Probleme schlecht strukturierter Datenbanken
Wenn deine Datenbank schlecht geplant ist, wird sie zum Alptraum. Redundanzen entstehen, wenn dieselben Informationen mehrfach gespeichert werden - das verschwendet Speicher und führt zu Chaos.
Änderungsanomalien treten auf, wenn du Daten aktualisieren willst, aber einen Datensatz übersiehst. Plötzlich hat dieselbe Person zwei verschiedene Adressen! Löschanomalien sind noch fieser: Du löschst einen Kunden und verlierst dabei ungewollt wichtige Produktdaten.
Einfügeanomalien zwingen dich, Dummydaten einzugeben, nur weil die Tabellenstruktur es verlangt. All diese Probleme führen zu Inkonsistenzen - Widersprüchen in deinen Daten.
Faustregel: Eine gut strukturierte Datenbank vermeidet Redundanzen und macht Änderungen einfach und sicher.
4
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
Entity-Relationship-Modell (ER-Modell)
Das ER-Modell ist wie ein Bauplan für deine Datenbank. Du identifizierst Entitäten (Objekte aus der Realität wie "Kunde" oder "Buch"), Attribute (Eigenschaften wie Name oder Preis) und Beziehungen (Zusammenhänge zwischen Entitäten).
Kardinalitäten beschreiben, wie viele Objekte miteinander verbunden sein können. Eine 1:n-Beziehung bedeutet: Ein Verlag hat viele Bücher, aber jedes Buch hat nur einen Verlag. Bei n:m-Beziehungen kann ein Kunde mehrere Bücher bestellen und ein Buch von mehreren Kunden bestellt werden.
Optionalität zeigt, ob eine Beziehung zwingend ist: Ein Kunde kann eine Rechnung erhalten (optional), aber eine Rechnung muss von einem Kunden stammen (Pflicht). Primärschlüssel werden im ER-Diagramm unterstrichen dargestellt.
Zeichentrick: Rechteck = Entität, Ellipse = Attribut, Raute = Beziehung - so einfach ist die ER-Notation!
5
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
Vom ER-Modell zur relationalen Datenbank
Jetzt wird's praktisch! Entitätstypen werden zu eigenständigen Tabellen, wobei der Primärschlüssel unterstrichen am Anfang steht. Die Attribute werden zu Spalten deiner Tabelle.
Beziehungen behandelst du je nach Typ unterschiedlich: m:n-Beziehungen bekommen eine eigene Tabelle. 1:n-Beziehungen ohne eigene Attribute löst du über Fremdschlüssel - der Primärschlüssel der "1"-Seite wandert als Fremdschlüssel zur "n"-Seite.
1:1-Beziehungen hängen von der Optionalität ab: Bei "kann-muss"-Beziehungen kommt der Primärschlüssel der "kann"-Seite als Fremdschlüssel zur "muss"-Seite. Die Farbcodierung hilft: Grün = eine Relation, Rot = zwei Relationen, Blau = drei Relationen.
Praxistipp: Lerne die Farbcodierung der Optimierungstabelle - sie spart dir viel Zeit bei der Umsetzung!
6
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
SQL-Grundlagen: Daten abfragen
SQL (Structured Query Language) ist deine Sprache, um mit der Datenbank zu sprechen. Der Grundaufbau ist simpel: SELECT (welche Spalten?), FROM (aus welcher Tabelle?), WHERE (unter welchen Bedingungen?).
Projektion filtert bestimmte Spalten heraus (SELECT Spalte FROM Tabelle). Mit dem Stern (SELECT *) holst du alle Spalten. Selektion filtert Zeilen nach Bedingungen (WHERE Bedingung).
UNION vereinigt zwei Tabellen mit identischem Schema - doppelte Einträge werden automatisch entfernt. JOIN verbindet zwei Tabellen über gemeinsame Attribute. Wichtig: Vermeide Cross-Joins, die jede Zeile der ersten mit jeder der zweiten Tabelle kombinieren!
Merksatz: SELECT = Spalten wählen, WHERE = Zeilen filtern, FROM = Tabelle angeben
7
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
JOIN-Varianten in SQL
INNER JOIN verbindet nur Datensätze, die in beiden Tabellen Entsprechungen haben. Das ist der Standard-Join für die meisten Abfragen. Die Syntax: FROM Tabelle1 INNER JOIN Tabelle2 ON Bedingung.
LEFT JOIN behält alle Datensätze der linken Tabelle, auch wenn keine Entsprechung in der rechten existiert. Fehlende Werte werden als NULL dargestellt. RIGHT JOIN macht das Gegenteil - alle Datensätze der rechten Tabelle bleiben erhalten.
Die Wahl des richtigen Joins hängt davon ab, welche Daten du behalten willst. INNER JOIN für exakte Übereinstimmungen, LEFT/RIGHT JOIN wenn du auch "unvollständige" Datensätze brauchst.
Eselsbrücke: LEFT JOIN = linke Tabelle vollständig, RIGHT JOIN = rechte Tabelle vollständig, INNER JOIN = nur Übereinstimmungen
8
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
Daten filtern und vergleichen
Vergleichsoperatoren machen deine WHERE-Klauseln mächtig. Neben den üblichen (<, >, =) gibt es praktische Helfer: BETWEEN für Bereiche, LIKE mit Wildcards (% für beliebig viele, _ für genau ein Zeichen) und IN für Listen.
Logische Operatoren (AND, OR, NOT) verknüpfen mehrere Bedingungen. IS NULL prüft auf leere Felder - wichtig, da NULL-Werte sich anders verhalten als normale Werte.
Die Verfeinerung der Ausgabe macht deine Ergebnisse professioneller: AS benennt Spalten um, ORDER BY sortiert (standardmäßig aufsteigend), DISTINCT entfernt Duplikate.
Tipp für die Praxis: LIKE-Wildcards sind super für Suchfunktionen -
LIKE '%Mueller%'findet "Mueller", "Müller" und "von Mueller"
9
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
Aggregatfunktionen und Berechnungen
Aggregatfunktionen fassen Daten zusammen und liefern einzelne Zahlenwerte. COUNT(*) zählt alle Datensätze, COUNT(DISTINCT Spalte) nur die verschiedenen Werte. SUM, MAX, MIN und AVG arbeiten mit Zahlenwerten.
Mathematische Operatoren (+, -, *, /) funktionieren auch in SQL. Du kannst direkt in der SELECT-Klausel rechnen oder Spalten miteinander verknüpfen.
Die Gruppierung mit GROUP BY teilt deine Daten in Gruppen auf und wendet Aggregatfunktionen auf jede Gruppe einzeln an. Wichtig: Alle Spalten im SELECT müssen entweder in GROUP BY stehen oder eine Aggregatfunktion haben.
Häufiger Fehler: Wenn du GROUP BY verwendest, müssen alle nicht-gruppierten Spalten eine Aggregatfunktion haben!
10
of 10Melde dich an, um den Inhalt zu sehen. Kostenlos!
- Zugriff auf alle Dokumente
- Verbessere deine Noten
- Schließ dich Millionen Schülern an
Mit der Anmeldung akzeptierst du die Nutzungsbedingungen und Datenschutzerklärung
Erweiterte SQL-Techniken
Geschachtelte SELECT-Ausdrücke (Unterabfragen) machen komplexe Abfragen möglich. Die innere Abfrage läuft zuerst und ihr Ergebnis wird als Bedingung für die äußere verwendet. Bei mehreren Ergebniswerten nutzt du den IN-Operator.
Aggregatfunktionen wie MIN und AVG helfen bei statistischen Auswertungen. Du kannst sie mit WHERE-Bedingungen kombinieren, um nur bestimmte Datensätze zu berücksichtigen.
Komplexere Abfragen entstehen durch Kombination verschiedener Techniken: JOINs mit Aggregatfunktionen, Unterabfragen mit Gruppierungen oder mehrere WHERE-Bedingungen mit logischen Operatoren.
Profi-Tipp: Teste komplexe Abfragen schrittweise - baue sie von innen nach außen oder von einfach zu komplex auf
Wir dachten schon, du fragst nie...
Unser KI-Begleiter ist ein speziell für Schüler entwickeltes KI-Tool, das mehr als nur Antworten bietet. Basierend auf Millionen von Knowunity-Inhalten liefert er relevante Informationen, personalisierte Lernpläne, Quizze und Inhalte direkt im Chat und passt sich deinem individuellen Lernweg an.
Du kannst die App im Google Play Store und im Apple App Store herunterladen.
Genau! Genieße kostenlosen Zugang zu Lerninhalten, vernetze dich mit anderen Schülern und hol dir sofortige Hilfe – alles direkt auf deinem Handy.
Ähnlicher Inhalt
Beliebtester Inhalt: SQL
2SQL-Befehle und Datenbankmodellierung
Erfahren Sie alles über grundlegende SQL-Befehle wie INSERT, SELECT, UPDATE und DELETE sowie die Modellierung relationaler Datenbanken. Diese Zusammenfassung behandelt auch das Entity-Relationship-Modell, Datenbanknormalisierung und wichtige SQL-Klauseln wie WHERE, GROUP BY und HAVING. Ideal für Studierende der Informatik, die ihre Kenntnisse in relationalen Datenbanken vertiefen möchten.
1210,634323
Webentwicklung Grundlagen
Erfahren Sie die Grundlagen der Webentwicklung mit HTML, CSS und PHP. Dieser umfassende Leitfaden behandelt die Erstellung von Webseiten, Datenbankanlegung mit SQL, Datenbanknormalisierung und die Verwendung von JOIN-Abfragen. Ideal für Abiturienten, die sich auf das Fach Informationsverarbeitung vorbereiten.
131,39638
Beliebtester Inhalt in Informatik
9Q
Quiz für die Komponenten des Pc's💻
💻Hier lernst ind testest du dein wissen über die Pc Komponenten⌨️
65974
C
Computer
Lerne alles über Computer und ihre Funktionsweise mit diesen fesselnden Flashcards. Perfekt für Schüler der 5. Klasse, die Computer Science entdecken möchten.
55440
Informatik Abitur 2025 NRW
Informatik Übersicht zu den Themen die im mündlichen Abitur drankommen. Ist also vielleicht nicht zu 100% vollständig.
124679
Informatik GK Lernzettel Abitur 2025
- selbstständig erstellter Lernzettel
1279118
WENN und SVERWEIS
Erklärung sverweis und wenn Funktion bei exel
116263
Python Lernzettel Informatik
Python Lernzettel (mathematische Operatoren, Variablen, Datentypen, Skripte, Boolesche Operatoren)
118899
Informatik Abitur 2024: Themenübersicht
Umfassende Themenübersicht für das Abitur 2024 im Fach Informatik. Dieser Lernzettel deckt wichtige Konzepte wie Programmierung in Java, Algorithmen, Datenstrukturen, Datenbanken, Cybersecurity und Verschlüsselungsmethoden ab. Ideal für Schüler, die sich auf das erhöhte Anforderungsniveau vorbereiten. Enthält auch Informationen zu relationalen Datenbanken, SQL-Abfragen und kryptologischen Verfahren.
132,86659
Relationale Datenbanken und SQL
Diese Zusammenfassung bietet einen umfassenden Überblick über relationale Datenbanken, einschließlich der Definition von Datensätzen, Attributen, Primär- und Fremdschlüsseln. Erfahren Sie mehr über Anomalien, ER-Diagramme und die Formulierung von SQL-Abfragen, um Daten effizient zu verwalten und zu analysieren. Ideal für Informatik-Abiturienten.
132,61765
Excel: Tabellen & Funktionen
Entdecken Sie die Grundlagen der Tabellenformatierung, wichtige Excel-Funktionen wie SUMME, MAX und WENN sowie die Erstellung von Diagrammen. Diese Zusammenfassung bietet klare Beispiele und Anleitungen für effektives Arbeiten mit Excel. Ideal für Studierende, die ihre Excel-Kenntnisse vertiefen möchten.
4,188139
Beliebtester Inhalt
9Der zerbrochene Krug
Szenenzusammenfassunfen, Figurenkonstellationen, Aufbau des Stücks, Sprache und Stilbesonderheiten, Aussageabsicht, Thematik, Interpretation
1148,107729
Heimsuchung_JennyErpenbeck_Abitur
Zusammenfassungen für jedes Kapitel, Analysen und Zitate
1314,164277
Lernzettel ZP 10 Mathe
Lernzettel von der ZP 10
105,350116
Schreibkompetenzen Deutsch LK
Diese umfassende Zusammenstellung bereitet auf das Abitur 2024 vor und deckt alle relevanten Schreibkompetenzen ab: von der Analyse pragmatischer Texte über die Erörterung literarischer Werke bis hin zur Interpretation von Epik, Lyrik und Dramatik. Zudem werden Techniken des materialgestützten Schreibens, der Redeanalyse sowie journalistische Textsorten und rhetorische Mittel behandelt. Ideal für eine gezielte und effektive Prüfungsvorbereitung.
138,223165
Mathe ZP10 Zusammenfassung NRW
Zusammenfassung der Mathethemwn für die ZP10 NRW + Formelsammlung
1010,195518
Der zerbrochene Krug Lernzettel & Zusammenfassung
Der zerbrochene Krug, Die wichtigsten Informationen zusammengefasst, Lernzettel
1323,506356
1
10 unregelmäßige Verben im past participle
unregelmäßige Verben aus Englisch - past participle
64,2783
Heimsuchung - Jenny Erpenbeck
Inhalt, Entstehung und Quellen, Figuren, Geschichtliche Hintergründe, Motive, Erzählstruktur/- stil
1134,810655
Führerschein Theorie Wiederholung/Notizen
Schilder, Zeichen, Zahlen, Vorfahrt und mehr - alles für die theoretische Führerscheinprüfung :)
119,082149
Schüler lieben uns — und du auch.
4.6/5App Store
4.7/5Google Play
Die App ist sehr einfach zu bedienen und gut gestaltet. Ich habe bisher alles gefunden, wonach ich gesucht habe, und konnte viel aus den Präsentationen lernen! Ich werde die App definitiv für ein Schulprojekt nutzen! Und natürlich hilft sie auch sehr als Inspiration.
Stefan SiOS-Nutzer
Diese App ist wirklich super. Es gibt so viele Lernzettel und Hilfen [...]. Mein Problemfach ist zum Beispiel Französisch und die App hat so viele Möglichkeiten zur Hilfe. Dank dieser App habe ich mich in Französisch verbessert. Ich würde sie jedem empfehlen.
Samantha KlichAndroid-Nutzerin
Wow, ich bin wirklich begeistert. Ich habe die App einfach mal ausprobiert, weil ich sie schon oft beworben gesehen habe und war absolut beeindruckt. Diese App ist DIE HILFE, die man für die Schule braucht und vor allem bietet sie so viele Dinge wie Übungen und Lernzettel, die mir persönlich SEHR geholfen haben.
AnnaiOS-Nutzerin